
In 2024, AWS launched Aurora Zero-ETL, Snowflake developed Snowpark, and Microsoft highlighted Real-Time Analytics. All herald the simplification of ETL pipelines and immediate access to data. But what does Zero-ETL really mean for
data teams?
In this context, the goal is not to systematically replace existing pipelines, but to assess where and how these new approaches can improve operational efficiency. This article offers a pragmatic analysis, based on field experience and concrete observations from data teams.
1. Zero-ETL: Understanding the Concept
Zero-ETL refers to a set of approaches that reduce or eliminate the traditional steps of extracting, transforming, and loading data before it can be used. The goal is to make data available more quickly while simplifying pipeline maintenance.
Three main approaches:
- Automated replication: automatic synchronization of data from operational systems to analytical warehouses (e.g. AWS Aurora → Redshift) with technologies such as Change Data Capture.
- Data virtualization: Data remains at its source, but is accessible via an abstraction layer (Databricks Lakehouse, Snowpark). This allows data to be queried as if it were centralized.
- Native streaming: Data streams are captured and transmitted continuously (Kafka Connect, CDC), providing near real-time availability.
What Zero-ETL doesn’t do:
- It does not eliminate all transformations. Some are still necessary for quality, compliance, or analysis.
- It doesn’t eliminate maintenance; the complexity shifts to configuration, monitoring, and stream optimization.
- It is not always applicable to all architectures, especially if the data is heterogeneous or very large.
2. Zero-ETL: Marketing promises vs. field reality
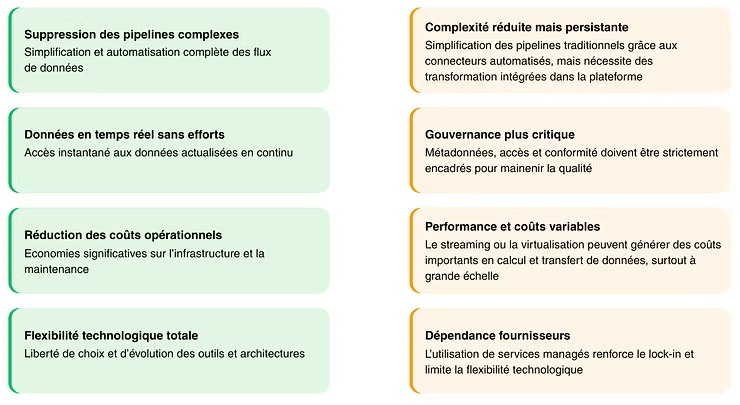
3. Use Case: When Zero-ETL Works
Zero-ETL is particularly effective in three contexts:
- Startups or structures with a simple architecture and few complex transformations.
- Precise analytical use cases, such as real-time KPI tracking or operational monitoring.
- Teams with limited ETL resources who want to accelerate data availability.
Concrete examples:
- Industry (SMEs and mid-sized companies): real-time analysis of production flows to adjust capacity and reduce costs.
- E-commerce: real-time synchronization of orders and stocks to anticipate stock shortages and adjust prices.
- B2B SaaS: Instantly feed executive dashboards with usage metrics.
- FinTech: transaction monitoring to quickly detect anomalies or fraud.
4. Pitfalls to avoid
- Zero code ≠ zero problems: configuration, monitoring and optimization remain essential.
- Underestimating governance: schemas, metadata and access must be properly managed.
- Forget scaling: What works at low volume can become expensive or slow at scale.
- Ignore hidden costs: raw storage, compute, network transfer can generate significant expenses.
5. Should we adopt Zero-ETL?
Consider Zero-ETL if:
- Need fresh or real-time data
- Homogeneous and modern sources
- ETL Team Limited
- Cloud environment already in place
Avoid if:
- Heavy or complex transformations
- Strict compliance constraints
- Very large volumes
- Need for technological flexibility
Questions to ask yourself:
- Maximum acceptable time between creation and exploitation of data?
- Sources, formats, schemas and update frequency?
- Current vs. projected costs?
- Team skills and governance requirements?
Conclusion
Zero-ETL is an attractive evolution for certain architectures and use cases, but it is not a one-size-fits-all solution. The decision should be based on the existing architecture, business needs, available skills, and associated costs.
To learn more, download our full study of 100 users, including statistics, benchmarks, and anonymized customer case examples.